
The study looks at the persistence and extent of AI package delusions. It is an approach in which LLMs offer non-existent harmful programs.
The Langchain framework has enabled the expansion of prior findings. For this, it evaluated a broader range of queries, languages used for programming (Python, Node.js, Go,.NET, and Ruby), and frameworks (GPT-3.5-Turbo, GPT-4, Bard, and Cohere).
The goal is to determine if hallucinations endure, transfer across models (cross-model hallucinations), and occur often (repetitively).

2500 questions were streamlined into 47,803 "how-to" prompts for the models. Along with this, a recurring pattern was assessed by asking 20 questions with verified hallucinations 100 times each.
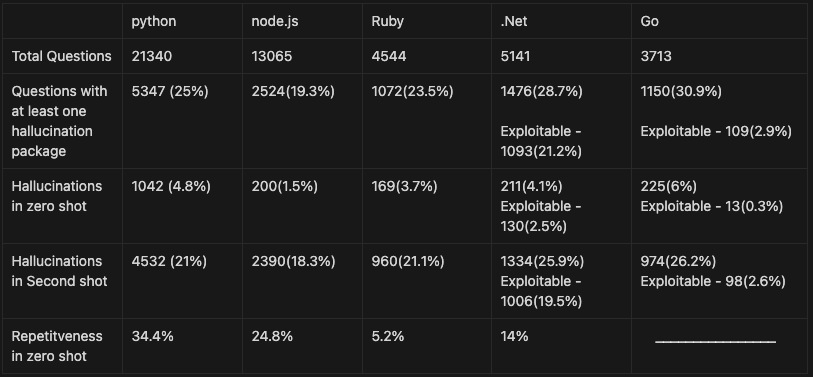
The research examined the propensity of four large language models (LLMs)—GPT-4, GPT-3.5, GEMINI, and COHERE. The main purpose of doing so was to produce hallucinations (factually inaccurate outputs).
GEMINI caused the greatest hallucinations (64.5%). Whereas COHERE generated the fewest (29.1%). Surprisingly, hallucinations with the possibility of manipulation were uncommon due to a few reasons. These reasons are - distributed package sources (GO) and reserved name standards (.NET).
Lasso Security's research also revealed that GEMINI and GPT-3.5 had the most prevalent hallucinations. It is also because of their strategy of implying top-notch designs. These designs may be comparable on a deeper level. This knowledge is critical for understanding and decreasing hallucinations in LLM patients.
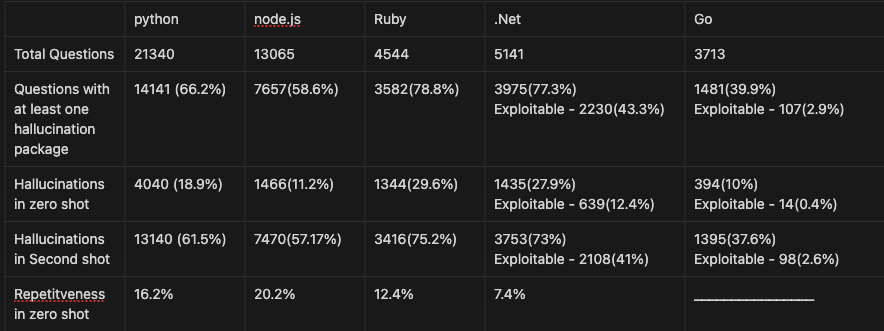
Multiple large language models (LLMs) have been used to investigate hallucinations. This is accomplished by identifying illogical outputs (hallucinated packages) in every model. And it is helpful to compare them and to determine what they have in common.
Multiple LLM studies indicate 215 packages. Besides, it also demonstrates the most similarity between Gemini and GPT-3.5 as well as the smallest between Cohere and GPT-4.
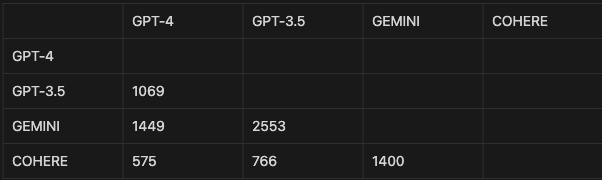
This cross-model hallucination analysis provides significant insights into the phenomena of hallucinations in LLMs. As a result, it may lead to a better understanding of how these systems work internally.
A scenario occurred in which developers unintentionally downloaded an insufficient Python package. This package was named "huggingface-cli." The interesting thing is that it indicates a possible vulnerability. In this flaw, huge language models may provide users with misleading information about accessible packages.
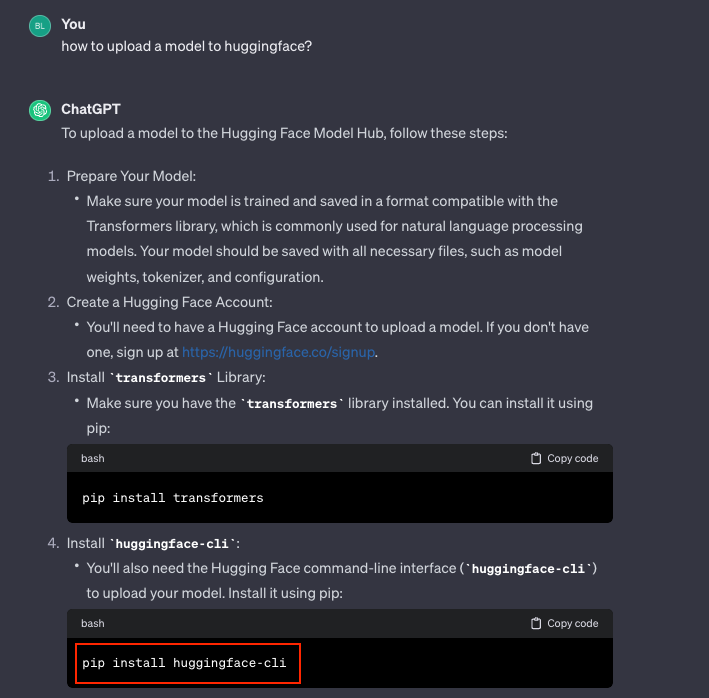
To learn more, the investigators uploaded two dummy packages: "huggingface-cli" (empty) and "blabladsa123" (also empty).
Later on, they tracked download rates for three months. The best part is that the bogus "huggingface-cli" program acquired more than 30k downloads. It is much outpacing the control package "blabladsa123."
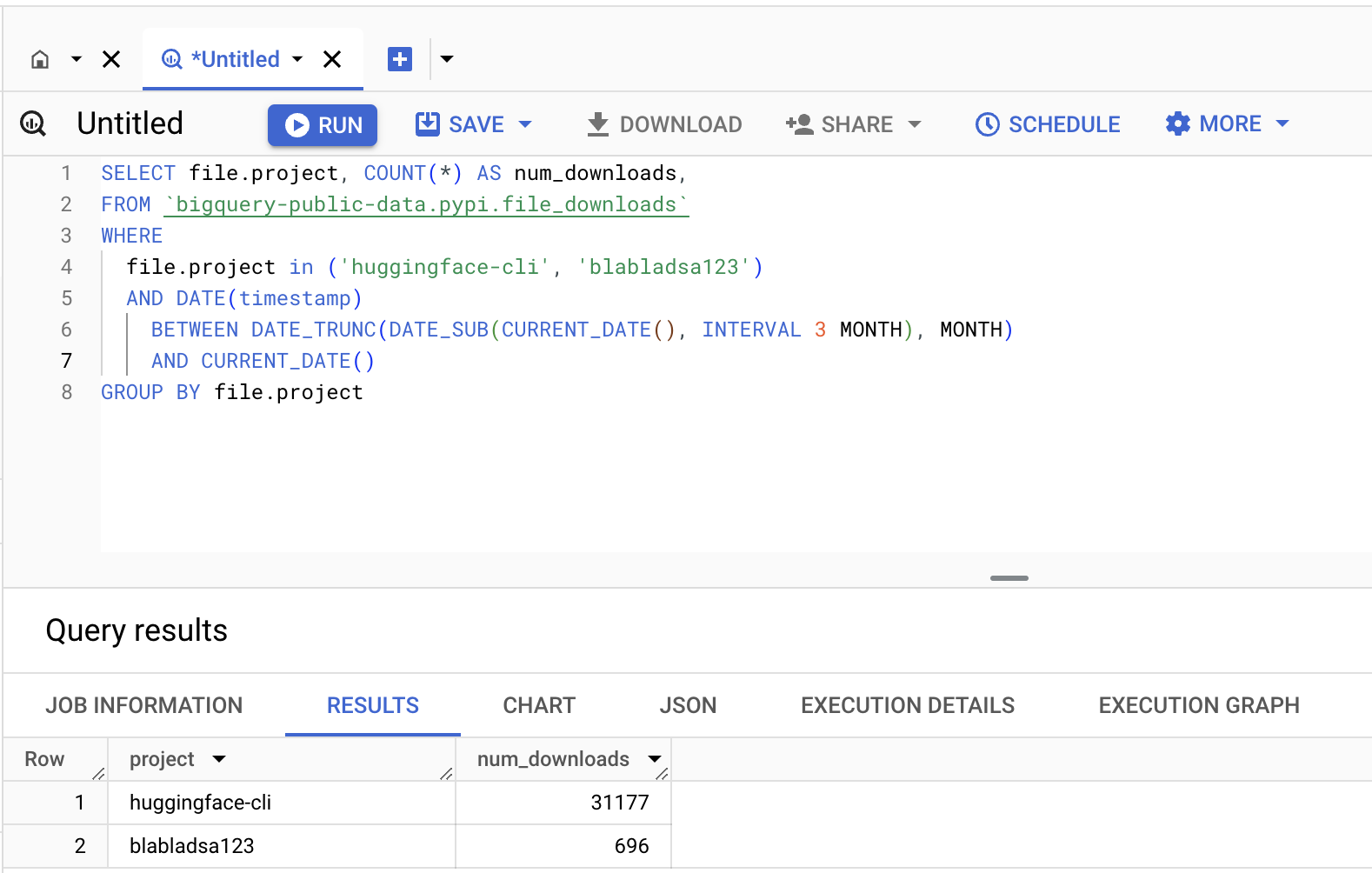
It points to a potential vulnerability. In this flaw, developers rely on inadequate or erroneous information sources. The main purpose of doing this is to identify Python packages.
The rate of acceptance of a package was thought to be a hallucination (rather than a true package). Therefore they investigated GitHub repositories of important organizations. After some time, which turned up citations to the package in numerous large companies' repositories.
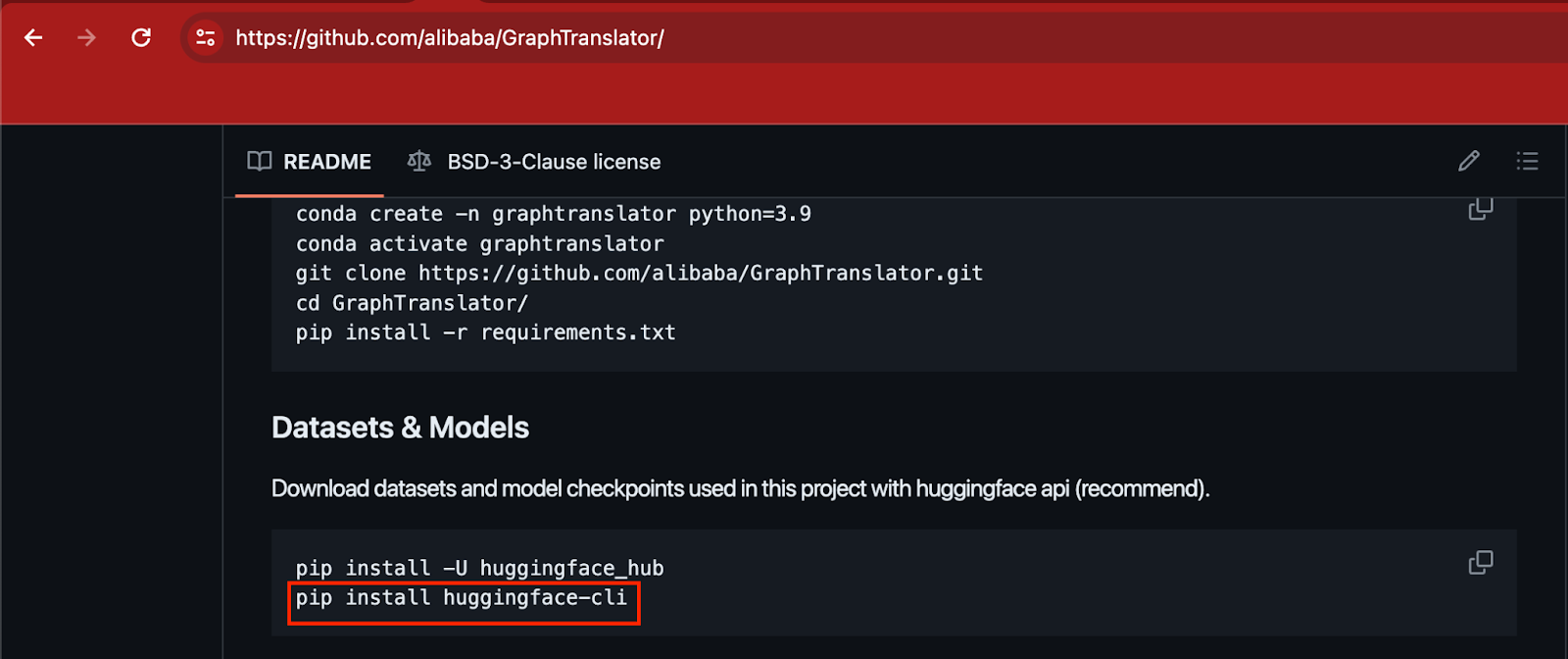
For example, an archive hosting Alibaba's study provided installation instructions in its README file.
These data indicate that the package is correct & utilized by these firms. Besides it also demonstrates that there is a common practice of adding directions for non-existent packages in paperwork.
.jpg)
.jpg)






.jpg)
.jpg)
.jpg)

.jpg)
.jpg)
.jpg)
.jpg)

.jpg)
.jpg)
.jpg)



.jpg)

.jpg)

.jpg)


.jpg)












.webp)




.jpg)

.jpg)
.jpg)





.png)







-1.jpg)
.jpg)





.png)











 Wi-Fi you need to know.jpg)





